
Non, vous ne rêvez pas, en ce 31 oct, je vous souhaite un joyeux Noël, malgré la période fort spéciale que nous vivons. J’en vois cependant qui protestent en affirmant que je me trompe de date. Ne savez-vous pas que 31 oct = 25 dec ?
Laissez-moi donc vous expliquer cette blague matheuse.
Question de base
Que signifient véritablement ces oct et ces dec ? Pas les mois d’octobre et de décembre, vous le comprendrez bien : ces trigrammes désignent en réalité la base dans laquelle il faut considérer le nombre que l’on lit : oct pour le système octal, en base 8, et dec pour le système décimal, en base 10.
Explications : Les nombres dont nous avons l’habitude sont écrits en base 10. Lorsque nous écrivons 124, nous désignons le nombre qui comporte 4 unités, 2 dizaines et 1 dizaine de dizaine (ou une centaine). Nous comptons par paquets de 10, puis par paquets de paquets de 10, et ainsi de suite.

Cette base 10 est bien commode puisqu’elle correspond au nombre de doigts que nous avons à nos mains et nous permet donc de compter dessus.
Seulement, je peux compter en d’autres bases, et en l’occurence, en base 8. Par exemple, si je considère le nombre 145 écrit en base 8, celui-ci vaut 5 unités, 4 huitaines et 1 huitaine de huitaine, c’est-à-dire 5 + 4 × 8 + 1 × 8 × 8, soit 111. Pour ne pas se mélanger dans toutes ces écritures, il est alors préférable de signaler la base dans lequel est écrit le nombre. Ainsi, ce nombre ci-dessus s’écrira 1458. Nous avons par ailleurs montré que 1458 = 11110.
Notez également qu’il ne faut pas prononcer ce nombre « cent quarante-cinq » : un nombre est indépendant de sa représentation dans une base, ce n’est là qu’une manière de l’écrire. Ainsi, « cent quarante-cinq », c’est bien sûr 14510, mais aussi 2218. A vous de faire le calcul.
Revenons alors à notre blague de début : 31 oct, c’est en fait 318, soit 3 huitaines et 1 unités. Avec un peu de calcul, on trouve alors 318 = 3 × 8 + 1 = 25. Ainsi, 318=2510.
Des bases partout !
Mais ces bases, où sont-elles utiles ? Eh bien, à de nombreux endroits… Petit florilège
Votre ordinateur, comme tout équipement électronique ou informatique, fonctionne grâce au système binaire : la base 2. Dans cette base, on n’utilise que le 0 ou le 1. Par exemple 110102 = 2610
Le système duodécimal, en base 12, est utilisé pour le partage de la journée en heures, et ce, depuis les égyptiens. Certains militent d’ailleurs pour que ce système remplace notre système décimal, nous en reparlerons une prochaine fois.
Vous vous demandez alors comment écrire un nombre en base 12 alors que l’on ne possède que 10 chiffres ? Eh bien, il faut en utiliser de nouveaux ! Des lettres par exemple. Dans le système duodécimal, suivant la mode, le chiffre correspondant à 10 est symbolisé par la lettre A, la lettre X ou un 2 à l’envers, ↊. Le 11 est symbolisé par la lettre B, la lettre E ou un 3 à l’envers, ↋. Ainsi, 2A312 = 3 + 10 × 12 + 2 × 12 × 12 = 41110.
Le système hexadécimal, en base 16. Vous l’avez peut-être rencontré dans les codes couleurs notamment. On utilise alors les lettres A, B, C, D, E et F pour 10, 11, 12, 13, 14 et 15
Le système vigésimal, en base 20, a été utilisé en France il y a bien longtemps. Nous en gardons une trace dans nos nombres modernes. En effet, 4020 = 8010… qui se prononce « quatre-vingts », correspondant à quatre vingtaines.
Le système sexagésimal, en base 60, remonte à l’époque babylonienne et on en trouve encore des traces aujourd’hui, lorsque l’on compte en heures et en minutes.
Certes, les civilisations citées ici n’écrivaient pas leurs nombres avec des 1, des 2 et des A, mais tout ceci a été adapté depuis. La règle est toujours la même lorsque l’on écrit un nombre dans une autre base : dans une base b, chaque chiffre est b fois plus important que le chiffre immédiatement à sa droite. C’est le principe de la notation positionnelle.
Et des bases non entières ?
Pourquoi faire simple quand on peut faire compliqué…
Connaissez-vous le nombre d’or φ ? Multiplier ce nombre par lui-même revient à lui ajouter 1. En d’autres termes, φ× φ = φ + 1, ou encore φ2 = φ + 1. Nous pourrions également l’utiliser comme base pour écrire des nombres. Par exemple, le nombre 10101φ vaut 1 + 0 × φ + 1 × φ2 + 0 × φ3 +1 × φ4 qui vaut… une certaine quantité, ce n’est pas intéressant.
Pourquoi ce nombre ?
Prenez par exemple 100φ. Cette écriture correspond à φ2. Or, par définition, φ2 = φ + 1. Mais φ + 1 s’écrit alors 11φ. Nous avons donc deux écritures différents pour un même nombre en base φ : 11φ = 100φ. Et ça devient gênant…
Rassurez-vous, il est possible de s’en sortir… Mais là aussi, ce sera une prochaine fois.
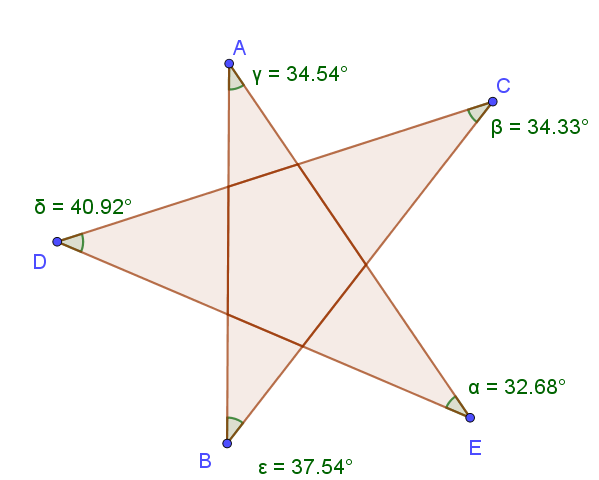

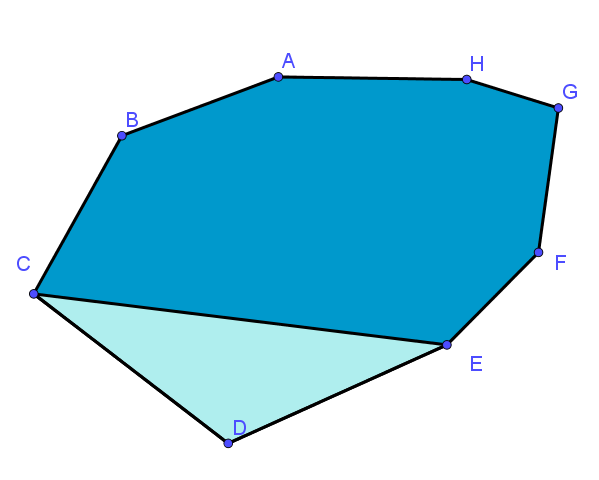 Un tel triangle est appelé « oreille du polygone ». Nous avons donc découpé notre polygone à n+1 sommets en deux polygones :
Un tel triangle est appelé « oreille du polygone ». Nous avons donc découpé notre polygone à n+1 sommets en deux polygones :

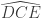 et
et  et ajouter l’angle extérieur en D.
et ajouter l’angle extérieur en D.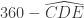 . Seulement,
. Seulement, 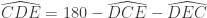 puisque la somme des angles du triangle CDE vaut 180°. L’angle extérieur en D vaut donc
puisque la somme des angles du triangle CDE vaut 180°. L’angle extérieur en D vaut donc 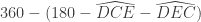 . On retranche alors les deux angles
. On retranche alors les deux angles 
















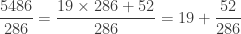 .
.








